
Moving on to the second set we move into the territory of breaking modern cryptography. We mainly concern ourselves with ECB and CBC mode and various ways to break systems that use these modes in an unsafe manner.
- Challenge 9: Implement PKCS#7 Padding
- Challenge 10: Implement CBC Mode
- Challenge 11: An ECB/CBC Detection Oracle
- Challenge 12: Byte-at-a-time ECB Decryption (Simple)
- Challenge 13: ECB Cut-and-paste
- Challenge 14: Byte-at-a-time ECB Decryption (Harder)
- Challenge 15: PKCS#7 Padding Validation
- Challenge 16: CBC Bitflipping Attacks
Challenge 9: Implement PKCS#7 Padding
In this challenge we have to implement PKCS#7 padding.
This is a fairly straightforward padding strategy. Given some sequence of bytes
and a block size we need to add padding bytes to the end of our sequence so that
the length of the sequence is a multiple of the block size. The padding bytes are
simply the byte representation of the number of bytes to pad. So if we need to add
six padding bytes then the padding would be b\x06\x06\x06\x06\x06\x06 i.e. six bytes
that are the byte representation of six. Python has the int.to_bytes function which
makes it easy to convert integers to bytes. The only edge case to consider is if the
sequence length is already a multiple of the block size. In that case we append
a full block of padding to the end of the byte sequence.
We can also verify the provided test vector in a python shell as an initial sanity check -
In [1]: pkcs7(b"YELLOW SUBMARINE", 20)
Out[1]: b'YELLOW SUBMARINE\x04\x04\x04\x04'
from Crypto.Cipher import AES
def pkcs7(data: bytes, block_size: int = AES.block_size) -> bytes:
bytes_to_pad = block_size - (len(data) % block_size)
padding_byte = int.to_bytes(bytes_to_pad, 1, byteorder='little')
padding = padding_byte * bytes_to_pad
return data + padding
def challenge09():
print(pkcs7(b"YELLOW SUBMARINE", 20))
Challenge 10: Implement CBC Mode
In this challenge we are tasked with implementing CBC mode decryption. CBC mode is another block cipher mode for encrypting plaintexts of an arbitrary length. If you read the appendix to the challenge 8 post CBC mode might already sound familiar. It helps us avoid some of the issues that the deterministic nature of ECB mode brings with it. The idea is to randomize the input to the cipher by first XOR-ing the plaintext block with the previous ciphertext block. If the cipher can be modeled as a pseudorandom function then each input to the cipher is pseudorandom since the input is the XOR of a plaintext block and the output of a pseudorandom function.
For the more visually inclined, Wikipedia has a nice diagram of this process.
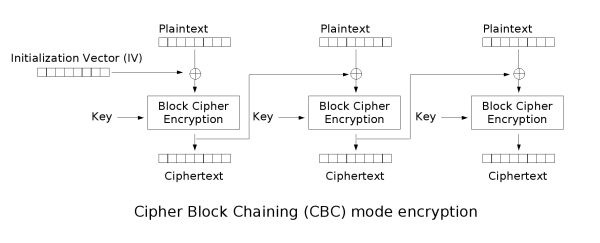
The decryption process is the reverse of this with the main “gotcha” being that we first apply the block cipher to the ciphertext block and then XOR the previous ciphertext block to obtain the plaintext block.
This addresses the ECB problem of equivalent plaintext blocks producing the same ciphertext blocks.
The only other consideration is that the first plaintext block does not have a previous
ciphertext block to XOR against. We solve this by passing an initialization vector (IV) as a
parameter to the encryption and decryption functions. This IV is randomly sampled and is what
the first plaintext block is XOR-ed against. One last thing to note: when we say randomly sampled
we are referring to the output of a CSPRNG.
That is to say, a random number generator specifically for cryptographic applications. In the case
of this challenge the IV is hardcoded to a known constant. In real applications this would cause
issues (we would instead want to use e.g. secrets.randbits to generate the IV).
from base64 import b64decode
from challenge02 import xor
from Crypto.Cipher import AES
def aes_cbc_decrypt(ctxt: bytes, key: bytes, iv: bytes) -> bytes:
ptxt = b''
cipher = AES.new(key, AES.MODE_ECB)
prev_block = iv
for block in range(len(ctxt) // AES.block_size):
start = block * AES.block_size
end = start + AES.block_size
cur_block = ctxt[start:end]
tmp = cipher.decrypt(cur_block)
ptxt += xor(prev_block, tmp)
prev_block = cur_block
return ptxt
def challenge10():
key = b'YELLOW SUBMARINE'
iv = b'\x00' * AES.block_size
with open('10.txt', 'rb') as f:
data = b64decode(f.read().replace(b'\n', b''))
print(aes_cbc_decrypt(data, key, iv))
Challenge 11: An ECB/CBC Detection Oracle
Having now got ECB mode and CBC mode under our belt, we are tasked with distinguishing ciphertexts encrypted in ECB and CBC mode. This is somewhat reminiscent of the IND-CPA game that is sometimes used to prove the security of an encryption scheme against a chosen plaintext attack. The gist of the black box whose output we must distinguish is -
- It takes an arbitrary sequence of bytes from us to encrypt.
- It generates a random AES key to use for the encryption.
- It prepends and appends some random bytes to the data we gave it.
- It flips a fair coin to decide whether to encrypt in ECB or CBC mode.
- It encrypts the data and returns it to us.
Luckily we already have pretty much all of the pieces we need to do this. In challenge 8 we already wrote a method to detect ECB mode that relied on there being two identical blocks in the ciphertext. In order to identify the encryption mode that the black box used we just have to make sure that two of the plaintext blocks it encrypts are the same. This is somewhat complicated by random data being prepended and appended to the plaintext. To address this we can craft a plaintext of one repeating character that is a sufficient length that two of the plaintext blocks in the middle will be equal, regardless of the data that is prepended and appended. We then run the ECB mode detector on the resulting ciphertext. If it detects ECB mode then we know the black box used ECB mode, otherwise we can be confident that the black box used CBC mode.
The only other thing to note here is that we also need to implement encryption for ECB and CBC mode. We already implemented decryption for ECB and CBC mode in challenges 7 and 10 respectively so these functions should look pretty familiar.
from os import urandom
from random import randint
from challenge02 import xor
from challenge08 import is_encrypted_in_ecb_mode
from challenge09 import pkcs7
from Crypto.Cipher import AES
def aes_ecb_encrypt(ptxt: bytes, key: bytes) -> bytes:
ctxt = b''
cipher = AES.new(key, AES.MODE_ECB)
padded = pkcs7(ptxt)
for block in range(len(padded) // AES.block_size):
start = block * AES.block_size
end = start + AES.block_size
ctxt += cipher.encrypt(padded[start:end])
return ctxt
def aes_cbc_encrypt(ptxt: bytes, key: bytes, iv: bytes) -> bytes:
ctxt = b''
cipher = AES.new(key, AES.MODE_ECB)
prev_block = iv
padded = pkcs7(ptxt)
for block in range(len(padded) // AES.block_size):
start = block * AES.block_size
end = start + AES.block_size
cur_block = padded[start:end]
tmp = xor(prev_block, cur_block)
ctxtblock = cipher.encrypt(tmp)
ctxt += ctxtblock
prev_block = ctxtblock
return ctxt
def encryption_oracle(data: bytes) -> bytes:
key = urandom(16)
randomized_data = urandom(randint(5, 10)) + data + urandom(randint(5, 10))
if randint(0, 1):
print('Encrypting in ECB mode...')
return aes_ecb_encrypt(data, key)
else:
print('Encrypting in CBC mode...')
iv = urandom(16)
return aes_cbc_encrypt(data, key, iv)
def challenge11():
ctxt = encryption_oracle(b'\x00' * 100)
if is_encrypted_in_ecb_mode(ctxt):
print('Detected ECB Mode')
else:
print('Detected CBC Mode')
Challenge 12: Byte-at-a-time ECB Decryption (Simple)
This is were things start to move from the realm of training wheels to practical attacks. In this challenge we are tasked with breaking an ECB encrypted ciphertext one byte at a time. This challenge is probably complex enough that rather than throwing a whole solution onto the end, as in previous challenges, we’re going to write out functions step by step as we go.
Preliminaries
The first component we need is an oracle that takes a byte sequence of our choosing, appends a constant byte sequence to the end, and encrypts those bytes under a constant key. Since we’ve got some state (the key and the appended byte sequence) to manage we’ll use a class to encapsulate this.
from os import urandom
from challenge11 import aes_ecb_encrypt
class EncryptionOracle:
def __init__(self, appended: bytes):
self.key = urandom(16) # 128 bit key for AES
self.appended = appended
def encrypt(self, data: bytes) -> bytes:
return aes_ecb_encrypt(data + self.appended, self.key)
With this context in mind, the objective in this problem is to figure out a way to recover the contents of the appended string using only this oracle. That’s pretty cool when you think about it! Given an unknown constant key and unknown constant sequence of bytes, and having only control over a chosen prefix, we can use an encryption oracle to decrypt the unknown sequence of bytes without ever learning the key! This also does not bode well for ECB mode (and things won’t get any better for ECB in the coming challenges).
Next we need to determine what the block size of the cipher is. This is already known to us, but the idea here is that a practical application of this attack might start with us not knowing any details such as block size, encryption mode, etc. Determining the block size can be achieved by passing incrementally larger data to the encryption oracle until the output length of the oracle changes. In other words, we increment the size of the byte sequence that the oracle encrypts by one byte until it crosses the boundary of a block. The difference in output lengths is then the block size of the cipher.
oracle = EncryptionOracle(b'') # we'll make this the actual appended bytes later
def detect_block_size() -> int:
data = b''
initial_len = cur_len = len(oracle.encrypt(data))
while cur_len == initial_len:
data += b'A'
cur_len = len(oracle.encrypt(data))
return cur_len - initial_len
For step (2) we can reuse our is_encrypted_in_ecb_mode function from
challenge 8. At step (3) we then use the block
size that we found earlier to craft an input such that the first byte of the appended byte
sequence is the last byte of the block we are encrypting. In other words we want to end up with
a block where only one byte is unknown to us. If we represent the unknown bytes in the appended
message with ? and have a block size of 8 then our prefix would be e.g. b'AAAAAAA' and
we would be encrypting the following blocks -
AAAAAAA? ???????? ...
^^^^^^^
prefix
Recovering A Single Byte
How is this prefix useful? It allows us to control the size of the search space. If an entire
block is unknown then there are 2^(8 * b) possible values that the block could have (where b
is the length of the block in bytes). On the other hand, if the first b-1 bytes are known then
the search space is 2^8. We can easily brute force that search space. So, say we get back a
ciphertext where for the first input block we knew all the bytes except for one. We can then craft
2^8 guesses that are the original prefix of A bytes plus a guess at the unknown byte.
b'A...A\x00'
b'A...A\x01'
b'A...A\x02'
...
b'A...A\xff'
We can then pass each of these guesses to the oracle to build a dictionary mapping of output ciphertext block to the last byte in that guess’ prefix. This creates a lookup of ciphertext block to plaintext byte.
from typing import Dict
def build_lookup_table(prefix: bytes) -> Dict[bytes, bytes]:
block_size = len(prefix) + 1 # operate under assumption that only 1 byte is unknown
lookup = {}
for byte_as_int in range(0x100):
byte = byte_as_int.to_bytes(1, byteorder="little")
guess = prefix + byte
ciphertext = oracle.encrypt(guess)
first_block = ciphertext[:block_size]
lookup[first_block] = byte
return lookup
We now have all the pieces we need to decrypt byte by byte. We use the following steps -
- Determine that the mode is ECB and that this attack is feasible.
- Determine the block size so that we know how to craft our prefixes.
- Craft a prefix such that one byte of an input block is unknown.
- Create a map of ciphertext block to unknown byte for every possible value of the unknown byte.
- Recover the unknown byte using the map.
def recover_byte() -> bytes:
block_size = detect_block_size()
prefix = b'A' * (block_size - 1)
ciphertext = oracle.encrypt(prefix)
target_ciphertext_block = ciphertext[:block_size]
lookup = build_lookup_table(prefix)
return lookup[target_ciphertext_block]
At this point it’s worth running a proof of concept to make sure that everything is working
as intended. We’ll initialize EncryptionOracle with b'secret' as the unknown string. We
then expect that recover_byte() will return b's' when we run it.
In [1]: from challenge12 import recover_byte
In [2]: recover_byte()
Out[2]: b's'
Extending to Multiple Bytes and Blocks
With the meat of the problem out of the way the rest of this problem takes us a bit out of the realm of purely cryptanalysis and into the realm of writing good control flow as well. The remaining questions to answer are -
- How do we break the next bytes in the first block?
- How do we break the bytes in subsequent blocks?
The first question has a pretty straightforward answer - we incorporate the byte we just recovered
into the next lookup table. So if e.g. we just recovered b's' then our new prefix becomes b'A..A' with
one less A. Our lookup prefix then becomes the A bytes plus the known bytes. In this way
we can recover the entire first block. The trick is that we always want to have exactly one unknown byte
in the block and that we want to keep incorporating the bytes we recover into our next lookup table.
Note that how we construct the lookup is adaptive and that we enclose things in a loop, but that the
core of the attack is not changed.
AAAAAAAAAAAAAAs?
^^^ input ^^^^
^^^^ known ^^^^
def recover_block() -> bytes:
known_bytes = b''
block_size = detect_block_size()
while len(known_bytes) != block_size:
a_bytes = block_size - len(known_bytes) - 1
prefix = b'A' * a_bytes
ciphertext = oracle.encrypt(prefix)
target_ciphertext_block = ciphertext[:block_size]
lookup = build_lookup_table(prefix + known_bytes)
known_bytes += lookup[target_ciphertext_block]
return known_bytes
We can test this with a longer appended byte sequence to verify we can decode an entire block. In this
case we’ll use the byte sequence b'secret message, do not distribute'.
In [1]: from challenge12 import recover_block
In [2]: recover_block()
Out[2]: b'secret message, '
Now all that’s left is to extend this to multiple blocks. This gets a little tricky in that the A byte
prefix is no longer a part of the lookup table prefix after the first block is recovered.
Instead it’s the block_size - 1 known bytes before the unknown byte that we use. There’s also an edge case when
moving across block boundaries where we need to cycle the size of our prefix from 0 back to 15 in order
to get a single unknown byte in the next block e.g. -
|=== block1 ===| |=== block2 ===| |=== block3 ===|
AAAAAAAAAAAAAAAs ecret message, ? ????????????????
^^^^ input ^^^^
^^^^^^^^^^^^ known ^^^^^^^^^^^^^
So in the case above b'ecret message, would be the lookup table prefix that we use.
def recover_appended_message() -> bytes:
known_bytes = b''
current_block = 0
block_size = detect_block_size()
target_length = len(oracle.encrypt(b''))
while len(known_bytes) != target_length:
block_start = current_block * block_size
block_end = block_start + block_size
a_bytes = block_size - (len(known_bytes) % block_size) - 1
prefix = b'A' * a_bytes
ciphertext = oracle.encrypt(prefix)
target_ciphertext_block = ciphertext[block_start:block_end]
if current_block == 0:
lookup_prefix = prefix + known_bytes
else:
lookup_prefix = known_bytes[-(block_size - 1):]
lookup = build_lookup_table(lookup_prefix)
known_bytes += lookup[target_ciphertext_block]
if len(known_bytes) % block_size == 0:
current_block += 1
return known_bytes
If we run this we’ll notice that we actually get an error!
In [1]: from challenge12 import recover_appended_message
In [2]: recover_appended_message()
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In [2], line 1
----> 1 recover_appended_message()
File challenge12.py, in recover_appended_message()
lookup_prefix = known_bytes[-(block_size - 1):]
lookup = build_lookup_table(lookup_prefix)
---> known_bytes += lookup[target_ciphertext_block]
print(known_bytes)
if len(known_bytes) % block_size == 0:
KeyError: b'<some byte sequence>'
Recall that we need to pad any input to AES to be a multiple of the block size and that we do
this with PKCS#7 padding. Assume that want to recover b'secret' but that all we know is that
we need to recover one block since that is the size of the ciphertext that the oracle gives back
when we do target_length = len(oracle.encrypt(b'')). Notice that the padding of what is
encrypted will actually change once we have recovered the six bytes of the message and try to recover
the padding.
#### Round 7 ####
AAAAAAAAAsecret\x01
^^input^^
^^^^ known ^^^^
==> known_bytes = b'secret\x01' after round 7
#### Round 8 ####
AAAAAAAAsecret\x02\x02
^^input^
^^^^ known ^^^????
We have a mismatch in this case. We recovered the b'\x01' padding byte in the seventh round, but then in
the eighth round that b'\x01' byte that we “know” is no longer valid since the padding is different and
our lookup fails as a result since we built a mapping based on a prefix that is not correct this round. So
we need to figure out a way to recover the unpadded message length. We can do this in a similar way that
we detected the block size. We pass the oracle input byte sequences that increase in size by one each
iteration. Once the ciphertext size changes we know that the size of the byte sequence is how many
padding bytes were initially in the padded plaintext.
def detect_appended_bytes_length() -> int:
data = b''
initial_len = cur_len = len(oracle.encrypt(data))
while cur_len == initial_len:
data += b'A'
cur_len = len(oracle.encrypt(data))
padding_bytes = len(data)
return initial_len - padding_bytes
We can then update our assignment of target_length to use this new, more accurate, method.
- target_length = len(oracle.encrypt(b''))
+ target_length = detect_appended_bytes_length()
In [1]: from challenge12 import recover_appended_message
In [2]: recover_appended_message()
Out[2]: b'secret message, do not distribute'
Optimizations
With a functional implementation under our belt we can now turn to optimizing a bit. We can’t
do much better on the time complexity front since we’re going to have to brute force each byte,
but we can improve space complexity. Note that for each round recovering a byte requires us
to build a map of all possible encryptions of the unknown byte. We don’t actually need this map.
Instead of the map we can just check for the right ciphertext block as we are generating the
ciphertexts that are the keys of the map, making it unnecessary to maintain a map at all. This
reduces our space complexity quite a bit each round since the map is the only data structure we
maintain. In big O terms we have reduced the space needed from O(2^8 * n) = O(n) to O(1)
(where n is the length of the byte sequence we are recovering and the constant factor accounts
for the size of the search space). In theory (aka big O terms) the time complexity is still the
same, but in practice it will be faster (unless the unknown byte is always b'\xff') since we
can short circuit once we find the match.
def recover_byte(prefix: bytes, target_block: bytes) -> bytes:
block_size = len(prefix) + 1 # operate under assumption that only 1 byte is unknown
for byte_as_int in range(0x100):
byte = byte_as_int.to_bytes(1, byteorder="little")
guess = prefix + byte
ciphertext = oracle.encrypt(guess)
first_block = ciphertext[:block_size]
if first_block == target_block:
return byte
raise ValueError(
f"Could not recover byte with prefix {prefix} and target block {target_block}"
)
We then update recover_appended_message to use this new function to recover bytes.
- lookup = build_lookup_table(lookup_prefix)
- known_bytes += lookup[target_ciphertext_block]
+ known_bytes += recover_byte(lookup_prefix, target_ciphertext_block)
With that our attack is complete. The full implementation can be found below.
from base64 import b64decode
from os import urandom
from challenge08 import is_encrypted_in_ecb_mode
from challenge11 import aes_ecb_encrypt
oracle = None
class EncryptionOracle:
def __init__(self, appended: bytes):
self.key = urandom(16) # 128 bit key for AES
self.appended = appended
def encrypt(self, data: bytes) -> bytes:
return aes_ecb_encrypt(data + self.appended, self.key)
def detect_block_size() -> int:
data = b'A'
initial_len = cur_len = len(oracle.encrypt(data))
while cur_len == initial_len:
data += b'A'
cur_len = len(oracle.encrypt(data))
return cur_len - initial_len
def detect_appended_bytes_length() -> int:
data = b''
initial_len = cur_len = len(oracle.encrypt(data))
while cur_len == initial_len:
data += b'A'
cur_len = len(oracle.encrypt(data))
padding_bytes = len(data)
return initial_len - padding_bytes
def recover_byte(prefix: bytes, target_block: bytes) -> bytes:
block_size = len(prefix) + 1 # operate under assumption that only 1 byte is unknown
for byte_as_int in range(0x100):
byte = byte_as_int.to_bytes(1, byteorder="little")
guess = prefix + byte
ciphertext = oracle.encrypt(guess)
first_block = ciphertext[:block_size]
if first_block == target_block:
return byte
raise ValueError(
f"Could not recover byte with prefix {prefix} and target block {target_block}"
)
def recover_appended_message() -> bytes:
known_bytes = b''
current_block = 0
block_size = detect_block_size()
target_length = detect_appended_bytes_length()
while len(known_bytes) != target_length:
block_start = current_block * block_size
block_end = block_start + block_size
a_bytes = block_size - (len(known_bytes) % block_size) - 1
prefix = b'A' * a_bytes
ciphertext = oracle.encrypt(prefix)
target_ciphertext_block = ciphertext[block_start:block_end]
if current_block == 0:
lookup_prefix = prefix + known_bytes
else:
lookup_prefix = known_bytes[-(block_size - 1):]
known_bytes += recover_byte(lookup_prefix, target_ciphertext_block)
if len(known_bytes) % block_size == 0:
current_block += 1
return known_bytes
def challenge12():
global oracle
appended = b64decode(
"Um9sbGluJyBpbiBteSA1LjAKV2l0aCBteSByYWctdG9wIGRvd24gc28gbXkg"
"aGFpciBjYW4gYmxvdwpUaGUgZ2lybGllcyBvbiBzdGFuZGJ5IHdhdmluZyBq"
"dXN0IHRvIHNheSBoaQpEaWQgeW91IHN0b3A/IE5vLCBJIGp1c3QgZHJvdmUg"
"YnkK"
)
oracle = EncryptionOracle(appended)
assert is_encrypted_in_ecb_mode(oracle.encrypt(b'A' * 100))
print(recover_appended_message())
Challenge 13: ECB Cut-and-paste
In this challenge we pick on poor ECB mode yet again. We are again going to exploit the fact that ECB deterministically encrypts each block, meaning that under the same key two equal plaintext blocks will encrypt to the same ciphertext blocks. This is where the “cut and paste” from the challenge title comes into play. You can arbitrarily swap the position of blocks within a ciphertext without turning the corresponding plaintext into gibberish. ECB also does not do anything to ensure the integrity of a ciphertext, we’d need to use a MAC or an authenticated encryption mode for that. So with ECB mode we can swap ciphertext blocks and the corresponding plaintext will also have the same blocks swapped.
Preliminaries
Before we start exploiting this property of ECB mode we need some preliminary utility functions. The
first is to decode a string (which the challenge calls a cookie) that is formatted like URL query parameters.
This format (in rough terms good enough for this challenge, don’t use this as a URL query param parsing
spec!) is a key value list, where keys and values are separated by = and key value pairs are separated
by &. So a string of key1=value1&key2=value2 would decode to the following dict in python -
{
"key1": "value1",
"key2": "value2"
}
While we could use something like the urllib.parse module
for this, it’s simple enough that we can implement our own that doesn’t have all the bells and whistles of parsing
a complete URL -
def decode_cookie(cookie: str) -> dict:
decoded = {}
for pair in cookie.split('&'):
key, value = pair.split('=')
decoded[key] = value
return decoded
We also need to write a profile_for function which takes an email and generates an encoded account object for
a user, with the role of 'user' and a user id. We need to encode the account object in the complementary process
to the parsing function we just wrote and return the encoded object as a string. We also need to ensure that we
escape the characters '&' and '=', lest we allow random key value pairs to be injected into the object via
the user specified email.
def profile_for(email: str) -> str:
sanitized_email = email.replace('&', '%26').replace('=', '%3D')
return f'email={sanitized_email}&uid=10&role=user'
We can then run a couple sanity checks to ensure that sanitization and parsing are working correctly -
In [1]: profile_object = decode_cookie(profile_for('foo@bar.com&role=admin'))
In [2]: assert profile_object['role'] == 'user'
In [3]: assert not profile_object['role'] == 'admin'
In [4]: assert profile_object['email'] == 'foo@bar.com%26role%3Dadmin'
Note that even though we tried to inject an admin role via the email the provided value was encoded and
thus we did not end up with an object where the 'role' key had value 'admin'. This is important
because we will be exploiting ECB mode to get an admin account, so we should convince ourselves that this
isn’t possible simply by injecting the role via the email field.
Cutting and Pasting ECB Blocks
We’re now asked to write two functions that rely on the same shared AES key. One to encrypt an encoded user profile and another to decrypt the profile and decode it.
from os import urandom
from challenge07 import aes_ecb_decrypt
from challenge11 import aes_ecb_encrypt
key = urandom(16)
def encrypt_encoded_profile(profile: str) -> bytes:
# note that encode call here means str => bytes, not profile object => str
profile_bytes = profile.encode()
return aes_ecb_encrypt(profile_bytes, key)
def decrypt_and_decode_profile(ciphertext: bytes) -> dict:
profile_bytes = aes_ecb_decrypt(ciphertext, key)
# note that decode here means bytes => str, not str => profile object
profile = profile_bytes.decode()
return decode_cookie(profile)
Now we have all the pieces we need for a cut and paste attack. Recall that cutting and pasting ciphertext blocks in ECB mode corresponds to the same operations on the plaintext. We can use this to create a plaintext where we have an account with the admin role. Consider this string -
email=hax0r@bar.admin___________com&uid=10&role=user<padding>
|--- block 1 --||--- block 2 --||--- block 3 --||--- block 4 --|
Note that we cut block 2 and paste it over block 4 to get the following string -
email=hax0r@bar.com&uid=10&role=admin___________
|--- block 1 --||--- block 2 --||--- block 3 --|
Now we have a string that looks like it will decode to an object with the admin role! All that is left is to ensure
the _ characters after admin are valid padding so that decryption doesn’t fail. Luckily we have already
implemented a function to generate valid padding in challenge 9.
Thus we implement our cut and paste attack -
from Crypto.Cipher import AES
from challenge09 import pkcs7
def cut_and_paste_attack() -> dict:
admin_block = pkcs7(b'admin')
email = 'hax0r@bar.' + admin_block.decode() + 'com'
encrypted_profile = encrypt_encoded_profile(profile_for(email))
# break profile into chunks the size of the AES block size
blocks = [
encrypted_profile[i * AES.blocksize:(i + 1) * AES.blocksize]
for i in range(len(encrypted_profile) // AES.blocksize)
]
encrypted_admin_profile = blocks[0] + blocks[2] + blocks[1]
return decrypt_and_decode_profile(encrypted_admin_profile)
Combining everything together we have our full attack, which validates that we did indeed generate an account with the admin role (we also get some style points for managing to have the email value be something that is formatted like a valid email).
def challenge13():
profile = cut_and_paste_attack()
print(profile)
assert profile['role'] == 'admin'
Note that if we run this the assertion fails! Why? Because we haven’t accounted for the padding bytes at the end of the message, which causes the profile object to look something like this -
{
'email': 'hax0r@bar.com',
'uid': '10',
'role': 'admin\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b'
}
We can take care of this by stripping the padding in our decrypt and decode function. This is what any production system
would also do, so no need to worry about this being “cheating”. This is also one of the times where getting back an int
when indexing a bytes sequence is a little annoying. It would be nice for this to work like string indexing in this case
and not have to convert the int back to bytes. Then again, there are other cases where this is a nice property.
def decrypt_and_decode_profile(ciphertext: bytes) -> dict:
profile_bytes = aes_ecb_decrypt(ciphertext, key)
padding_byte = profile_bytes[-1].to_bytes(1, byteorder='little')
profile_bytes = profile_bytes.rstrip(padding_byte)
# note that decode here means bytes => str, not str => profile object
profile = profile_bytes.decode()
return decode_cookie(profile)
The complete attack is below -
from os import urandom
from Crypto.Cipher import AES
from challenge07 import aes_ecb_decrypt
from challenge09 import pkcs7
from challenge11 import aes_ecb_encrypt
key = urandom(16)
def decode_cookie(cookie: str) -> dict:
decoded = {}
for pair in cookie.split('&'):
key, value = pair.split('=')
decoded[key] = value
return decoded
def profile_for(email: str) -> str:
sanitized_email = email.replace('&', '%26').replace('=', '%3D')
return f'email={sanitized_email}&uid=10&role=user'
def encrypt_encoded_profile(profile: str) -> bytes:
# note that encode call here means str => bytes, not profile object => str
profile_bytes = profile.encode()
return aes_ecb_encrypt(profile_bytes, key)
def decrypt_and_decode_profile(ciphertext: bytes) -> dict:
profile_bytes = aes_ecb_decrypt(ciphertext, key)
padding_byte = profile_bytes[-1].to_bytes(1, byteorder='little')
profile_bytes = profile_bytes.rstrip(padding_byte)
# note that decode here means bytes => str, not str => profile object
profile = profile_bytes.decode()
return decode_cookie(profile)
def cut_and_paste_attack() -> dict:
admin_block = pkcs7(b'admin')
email = 'hax0r@bar.' + admin_block.decode() + 'com'
encrypted_profile = encrypt_encoded_profile(profile_for(email))
# break profile into chunks the size of the AES block size
blocks = [
encrypted_profile[i * AES.block_size:(i + 1) * AES.block_size]
for i in range(len(encrypted_profile) // AES.block_size - 1)
]
encrypted_admin_profile = blocks[0] + blocks[2] + blocks[1]
return decrypt_and_decode_profile(encrypted_admin_profile)
def challenge13():
profile = cut_and_paste_attack()
assert profile['role'] == 'admin'
print(profile)
Appendix: Variable Data
One of the nice things about the profile object is that only the email is variable, so the attacker controls all the variable data. Suppose that the uid was also variable -
email=hax0r@bar.admin___________com&uid=<unknown>&role=user<padding>
|--- block 1 --||--- block 2 --||--- block 3 ???????? block 4 --|
This makes things more difficult as the boundary between block 3 and block 4 is now unknown and we
can’t be sure that role= is the end of the penultimate block. In this case some trial and error
may be necessary. If we make some assumptions about user ids, such as that they are assigned
incrementally, then we should still be able to find the length of the uid fairly quickly. We can
keep increasing the size of the string after admin___________ (i.e. the attacker controlled part
of block 3) until the resulting ciphertext changes in size. At that point we know that the last
block is all padding -
email=hax0r@bar.admin___________<our prefix>&uid=<unknown>&role=user<padding>
|--- block 1 --||--- block 2 --||--- block 3 ??????????? block 4 --||--- block 5 --|
At that point some algebra gives us ther size of uid
len_uid = AES.blocksize * 2 - len(our_prefix) - len('&uid=') - len('&role=user')
We can then craft a prefix such that role= is again the end of its block. That prefix needs to
have a length of
prefix_len = AES.block_size - len('com&uid=') - len_uid - len('&role=')
In the case where prefix_len is negative (i.e. uid is large enough that it spills into the next block(s))
then we simply add AES.block_size to the prefix_len until it is positive.
Challenge 14: Byte-at-a-time ECB Decryption (Harder)
This challenge modifies challenge 12, so check out that post first as a preliminary. The difference is that in this challenge we prepend a random prefix to our input before encrypting via the oracle. Recall that in challenge 12 the oracle appended the target bytes to our input. In this challenge the oracle sandwiches our input between random bytes and the target bytes.
This means we’ll need to modify our oracle class a bit. It’s important to note that the random prefix bytes are constant across oracle calls. We generate them once and then append them to every input that the encyption oracle is queried on.
from os import urandom
from random import randint
from challenge11 import aes_ecb_encrypt
class EncryptionOracle:
def __init__(self, appended: bytes):
self.key = urandom(16) # 128 bit key for AES
self.appended = appended
prefix_bytes = randint(1, 100)
self.prefix = urandom(prefix_bytes)
def encrypt(self, data: bytes) -> bytes:
return aes_ecb_encrypt(self.prefix + data + self.appended, self.key)
So why is this harder? It’s more challenging because we don’t know exactly where the block boundary is right away, which means we’ll have a harder time figuring out the length of the data that we want to input in order to ensure only one unknown byte is in our block. There’s also an additional complication that we need to make sure that none of the prefix bytes get into our target block. If they do then we’ll be unable to properly create our lookup table since we’ll have unknown random bytes in the start of our input that will potentially vastly increase the search space.
So first let’s find a way to identify block boundary between our input and the target data. Our
strategy is to start with input data of one byte less than 3 blocks worth of the same byte. This guarantees
that we have two exactly equal ciphertext blocks. We then reduce the size of the input by one byte until
we no longer have two equal ciphertext blocks. When this happens we know that the difference between
plaintexts must look as follows (we use the 'A' character as the repeating byte we inject in this example)
Previous Round:
<unknown prefix>A..AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA<target>...<padding>
|--- block 1..n-2 ||-- block n-1 -||--- block n --||-- block n+1 ..._-|
Current Round
<unknown prefix>A..AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA<target>...<padding>
|--- block 1..n-2 ||-- block n-1 -||--- block n --||-- block n+1 ...-|
So we know where block n is based on the previous round, namely it’s the second block of the two matching
blocks in the previous round. Block n-1 is then the target block that we use as a starting point for our
byte at a time decryption (we can forego the entire block of duplicate bytes in the attack as this was only
useful for our ECB detection trick that allows us to find the block boundary). So we’ll want to return both
n-1, the target block index, and also the number of bytes that we should use to extend the random prefix to
the next block boundary. Note that in the example below we use 0x00 rather than 'A' as the target message
is much less likely to start with a zero byte and throw off our offset length.
from typing import Tuple
from challenge08 import is_encrypted_in_ecb_mode
oracle = EncryptionOracle(b'target')
def get_pad_length_and_start_block(block_size: int) -> Tuple[int, int]:
repeating_bytes = (3 * block_size - 1) * b'\x00'
ciphertext = oracle.encrypt(repeating_bytes)
assert is_encrypted_in_ecb_mode(ciphertext)
target_block_index = -1
for i in range(len(ciphertext) // block_size - 1):
block_start = i * block_size
block_end = next_block_start = block_start + block_size
next_block_end = next_block_start + block_size
block = ciphertext[block_start:block_end]
next_block = ciphertext[next_block_start:next_block_end]
if block == next_block:
target_block_index = i
break
while is_encrypted_in_ecb_mode(ciphertext):
repeating_bytes = repeating_bytes[:-1]
ciphertext = oracle.encrypt(repeating_bytes)
pad_length = len(repeating_bytes) - (block_size * 2 - 1)
return pad_length, target_block_index
This is tricky enough that it’s probably worth writing a small test driver to verify that these values are what we expect. We run a couple rounds of the function against random prefixes and check that (1) the pad length plus the prefix length is a multiple of the block size and (2) that we identify the correct block (the next full block after the prefix) as the target block.
def test_get_pad_length_and_start_block():
global oracle
block_size = 16
for _ in range(100):
oracle = EncryptionOracle(b'target')
prefix_len = len(oracle.prefix)
pad_length, block_index = get_pad_length_and_start_block(block_size)
assert (prefix_len + pad_length) % block_size == 0
assert (prefix_len + pad_length) // block_size == block_index
test_get_pad_length_and_start_block()
Once we’ve convinced ourselves that this is working we’ve completed the brunt of the challenge. All that’s left is to integrate these new constraints into our challenge 12 solution. We’ll do this by discussing the diffs between the challenge 12 functions and the challenge 14 functions (I’m sorry if this gives anyone flashbacks to reviewing merge requests at work). Functions that did not change are omitted.
def recover_appended_message() -> bytes:
known_bytes = b''
- current_block = 0
block_size = detect_block_size()
- target_length = detect_appended_bytes_length()
+ pad_length, start_block = get_pad_length_and_start_block(block_size)
+ random_prefix_length = start_block * block_size - pad_length
+ target_length = detect_appended_bytes_length(random_prefix_length)
+ current_block = start_block
+ constant_pad_bytes = b'A' * pad_length
while len(known_bytes) != target_length:
block_start = current_block * block_size
block_end = block_start + block_size
a_bytes = block_size - (len(known_bytes) % block_size) - 1
- prefix = b'A' * a_bytes
+ prefix = constant_pad_bytes + (b'A' * a_bytes)
ciphertext = oracle.encrypt(prefix)
target_ciphertext_block = ciphertext[block_start:block_end]
- if current_block == start_block:
+ if current_block == 0:
lookup_prefix = prefix + known_bytes
else:
- lookup_prefix = known_bytes[-(block_size - 1):]
+ lookup_prefix = constant_pad_bytes + known_bytes[-(block_size - 1):]
- known_bytes += recover_byte(lookup_prefix, target_ciphertext_block)
+ known_bytes += recover_byte(
+ lookup_prefix, target_ciphertext_block, start_block, block_size
+ )
if len(known_bytes) % block_size == 0:
current_block += 1
return known_bytes
This is the core of the algorithm and also has the most changes to absorb. We start
by calculating the starting block and the number of bytes needed to pad the random
prefix to a multiple of the block size. We then also derive the length of the random
prefix. We update current_block accordingly, having the algorithm start on the first
block after the random prefix. We also calculate constant_pad_bytes which are used
to ensure that we always pad out the prefix to the end of a full block. You can see
that these bytes are prepended throughout the algorithm. The remaining changes are to
existing method calls that now need additional parameters. Let’s look at one of those,
recover_byte, next.
-def recover_byte(prefix: bytes, target_block: bytes) -> bytes:
+def recover_byte(
+ prefix: bytes, target_block: bytes, target_index: int, block_size: int
+) -> bytes:
- block_size = len(prefix) + 1 # operate under assumption that only 1 byte is unknown
-
for byte_as_int in range(0x100):
byte = byte_as_int.to_bytes(1, byteorder="little")
guess = prefix + byte
ciphertext = oracle.encrypt(guess)
- first_block = ciphertext[:block_size]
+ guess_block = ciphertext[target_index * block_size:(target_index + 1) * block_size]
- if first_block == target_block:
+ if guess_block == target_block:
return byte
raise ValueError(
f"Could not recover byte with prefix {prefix} and target block {target_block}"
)
The main change here is that we cannot assume that the first block is the block that the attacker (AKA us) controls. We must instead use the first block after the random prefix as the attacker controlled block that we can use to generate ciphertexts for our search space. This boils down to some extra parameters that help us index that block correctly.
The last change we need to make is in how we detect the size of the target message.
-def detect_appended_bytes_length() -> int:
+def detect_appended_bytes_length(random_prefix_length: int) -> int:
data = b''
initial_len = cur_len = len(oracle.encrypt(data))
while cur_len == initial_len:
data += b'A'
cur_len = len(oracle.encrypt(data))
padding_bytes = len(data)
- return initial_len - padding_bytes
+ return initial_len - padding_bytes - random_prefix_length
This is also fairly straight forward. We just have to account for the random prefix
in our calculation. Since we already derive the length of the random prefix in the
recover_appended_message function we just pass it as a parameter and then subtract
the length from the value we get using the challenge 12 algorithm. Putting it all
together we arrive at the following solution.
from base64 import b64decode
from os import urandom
from random import randint
from typing import Tuple
from challenge08 import is_encrypted_in_ecb_mode
from challenge11 import aes_ecb_encrypt
oracle = None
class EncryptionOracle:
def __init__(self, appended: bytes):
self.key = urandom(16) # 128 bit key for AES
self.appended = appended
prefix_bytes = randint(1, 100)
self.prefix = urandom(prefix_bytes)
def encrypt(self, data: bytes) -> bytes:
return aes_ecb_encrypt(self.prefix + data + self.appended, self.key)
def get_pad_length_and_start_block(block_size: int) -> Tuple[int, int]:
repeating_bytes = (3 * block_size - 1) * b'\x00'
ciphertext = oracle.encrypt(repeating_bytes)
assert is_encrypted_in_ecb_mode(ciphertext)
target_block_index = -1
for i in range(len(ciphertext) // block_size - 1):
block_start = i * block_size
block_end = next_block_start = block_start + block_size
next_block_end = next_block_start + block_size
block = ciphertext[block_start:block_end]
next_block = ciphertext[next_block_start:next_block_end]
if block == next_block:
target_block_index = i
break
while is_encrypted_in_ecb_mode(ciphertext):
repeating_bytes = repeating_bytes[:-1]
ciphertext = oracle.encrypt(repeating_bytes)
pad_length = len(repeating_bytes) - (block_size * 2 - 1)
return pad_length, target_block_index
def detect_block_size() -> int:
data = b'A'
initial_len = cur_len = len(oracle.encrypt(data))
while cur_len == initial_len:
data += b'A'
cur_len = len(oracle.encrypt(data))
return cur_len - initial_len
def detect_appended_bytes_length(random_prefix_length: int) -> int:
data = b''
initial_len = cur_len = len(oracle.encrypt(data))
while cur_len == initial_len:
data += b'A'
cur_len = len(oracle.encrypt(data))
padding_bytes = len(data)
return initial_len - padding_bytes - random_prefix_length
def recover_byte(
prefix: bytes, target_block: bytes, target_index: int, block_size: int
) -> bytes:
for byte_as_int in range(0x100):
byte = byte_as_int.to_bytes(1, byteorder="little")
guess = prefix + byte
ciphertext = oracle.encrypt(guess)
guess_block = ciphertext[target_index * block_size:(target_index + 1) * block_size]
if guess_block == target_block:
return byte
raise ValueError(
f"Could not recover byte with prefix {prefix} and target block {target_block}"
)
def recover_appended_message() -> bytes:
known_bytes = b''
block_size = detect_block_size()
pad_length, start_block = get_pad_length_and_start_block(block_size)
random_prefix_length = start_block * block_size - pad_length
target_length = detect_appended_bytes_length(random_prefix_length)
current_block = start_block
constant_pad_bytes = b'A' * pad_length
while len(known_bytes) != target_length:
block_start = current_block * block_size
block_end = block_start + block_size
a_bytes = block_size - (len(known_bytes) % block_size) - 1
prefix = constant_pad_bytes + (b'A' * a_bytes)
ciphertext = oracle.encrypt(prefix)
target_ciphertext_block = ciphertext[block_start:block_end]
if current_block == start_block:
lookup_prefix = prefix + known_bytes
else:
lookup_prefix = constant_pad_bytes + known_bytes[-(block_size - 1):]
known_bytes += recover_byte(
lookup_prefix, target_ciphertext_block, start_block, block_size
)
if len(known_bytes) % block_size == 0:
current_block += 1
return known_bytes
def challenge14():
global oracle
appended = b64decode(
"Um9sbGluJyBpbiBteSA1LjAKV2l0aCBteSByYWctdG9wIGRvd24gc28gbXkg"
"aGFpciBjYW4gYmxvdwpUaGUgZ2lybGllcyBvbiBzdGFuZGJ5IHdhdmluZyBq"
"dXN0IHRvIHNheSBoaQpEaWQgeW91IHN0b3A/IE5vLCBJIGp1c3QgZHJvdmUg"
"YnkK"
)
oracle = EncryptionOracle(appended)
assert is_encrypted_in_ecb_mode(oracle.encrypt(b'A' * 100))
print(recover_appended_message())
Challenge 15: PKCS#7 Padding Validation
We get a nice break in this challenge from the more code (and brain) intensive challenges that we’ve had since challenge 12. Here the task is simple. Implement PKCS#7 padding validation. We’ve already implemented the padding itself in challenge 9, so we can reference that challenge for the details of the padding scheme.
There isn’t much more to add here, the challenge recommends throwing an exception, but we’ll
use a bool return type here. The effect is the same, but the interface feels a little cleaner.
from Crypto.Cipher import AES
def is_valid_pkcs7_padding(data: bytes, block_size: int = AES.block_size) -> bool:
pad_byte = data[-1]
if pad_byte > block_size or pad_byte <= 0:
return False
return all([ # all padding bytes must match the expected value
data_byte == pad_byte # check that the padding byte has the expected value
for data_byte in data[-pad_byte:] # iterate over each padding byte
])
def challenge15():
assert is_valid_pkcs7_padding(b'ICE ICE BABY\x04\x04\x04\x04')
assert not is_valid_pkcs7_padding(b'ICE ICE BABY\x05\x05\x05\x05')
assert not is_valid_pkcs7_padding(b'ICE ICE BABY\x01\x02\x03\x04')
print('All provided test vectors passed')
Challenge 16: CBC Bitflipping Attacks
In the final challenge of the second set we ease up on poor ECB mode and pick on CBC mode instead. While ECB mode is commonly shunned in “serious” production systems, we see CBC mode quite a lot. In fact, as recently as TLS 1.2 CBC mode was used to secure HTTPS traffic. If there is a takeaway from this challenge it’s that using the right cryptographic primitives often isn’t enough. You have to combine and apply them correctly too in order to have a safe system. Even big, respected TLS implementations like openSSL have learned this the hard way.
Preliminaries
Anyway, let’s flip some bits for fun and profit. Before we do that we have a couple
preliminaries we need to set up again to act as the canvas upon which we will paint our
attack. The first function we need to write is one which takes some bytes that we provide
and sets the userdata field of an object to that value. The data is then encrypted in
CBC mode under a random AES key.
from os import urandom
from challenge11 import aes_cbc_encrypt
from Crypto.Cipher import AES
key = urandom(AES.block_size)
iv = urandom(AES.block_size)
def set_and_encrypt_data(user_data: bytes) -> bytes:
sanitized = user_data.replace(b';', b'%3B').replace(b'=', b'%3D')
comment1 = b'comment1=cooking%20MCs;userdata='
comment2 = b';comment2=%20like%20a%20pound%20of%20bacon'
user = comment1 + sanitized + comment2
return aes_cbc_encrypt(user, key, iv)
We also sanitize the input so that injecting arbitrary fields via user_data is not possible.
This is relevant to the next function, which decrypts and checks if there is an admin field which
is set to true. Sanitization of the input ensures that we can’t simply inject user_data with
a substring of ;admin=true;.
from challenge10 import aes_cbc_decrypt
def is_admin(encrypted_data: bytes) -> bool:
user = aes_cbc_decrypt(encrypted_data, key, iv)
user_object = {}
for field in user.split(b';'):
field_name, value = field.split(b'=')
user_object[field_name] = value
return user_object.get(b'admin') == b'true'
At this point we can check that our sanitization is working correctly by trying to inject an admin role.
In [1]: encrypted = set_and_encrypt_data('foo;admin=true')
In [2]: is_admin(encrypted)
Out[2]: False
The Bitflipping Attack
Luckily for us the integrity of the ciphertext is not verified and we are free to modify it as we like before
sending it to the is_admin function. This is where the bitflipping comes into play. Recall that encryption in
CBC mode, applied to the input we have in this problem, looks something like this -
|comment1=cooking| |%20MCs;userdata=| |<attacker data>|
| | |
V V V
|... IV bytes ...|---> XOR +------> XOR +-------> XOR
| | | | |
V | V | V
AES | AES | AES
| | | | |
V | V | V
| ciphertext | -+ | ciphertext | -+ | ciphertext | ->...
Decryption is then as follows -
| ciphertext | -+ | ciphertext | -+ | ciphertext |
| | | | |
V | V | V
AES | AES | AES
| | | | |
V | V | V
|... IV bytes ...|---> XOR +------> XOR +------> XOR
| | |
V V V
|comment1=cooking| |%20MCs;userdata=| |<attacker data>|
Let’s use some terms to keeps things consistent and say that P0 is the first plaintext
block and C0 is the first ciphertext block (with P1 and C1 being the second block and
so on). We’ll also say that A is the input block of the plaintext that we control and that
T is the target block that we want to have as part of the decrypted output. In the decryption
process we know that P2 = A, which means we also can determine the output of AES(C2),
the AES decryption call, before the XOR is applied -
AES(C2) = C1 XOR A
We can’t change the value of AES(C2), but nothing is preventing us from swapping out C1 for
some value that we control. We want to switch out C1 for a new value, let’s call it C1',
such that C1' XOR AES(C2) = T. We derive it thus -
C1' = T XOR AES(C2) = T XOR C1 XOR A
Note that we control A, can choose T, and have knowledge of C1 so we can craft
this C1' block for any T that we arbitrarily choose. There is one side effect - P1 is now
going to be complete gibberish since we are passing it a modified ciphertext block. That means
that our T block will need to prepend ; to whatever data we want to set in order to ensure
that the gibberish does not spill over to the data we want to inject.
from challenge02 import xor
def replace_ciphertext_block(target: bytes, ctxt: bytes, user_data: bytes) -> bytes:
target_ciphertext_block = ctxt[AES.block_size:2 * AES.block_size] # C1
decrypted_before_xor = xor(target_ciphertext_block, user_data) # AES(C2)
modified_ciphertext_block = xor(target, decrypted_before_xor) # C1'
start = ctxt[:AES.block_size]
end = ctxt[2 * AES.block_size:]
return start + modified_ciphertext_block + end
Visually this is what we have done in replacing the second ciphertext block -
| C0 | -+ | T XOR C1 XOR A | -+ | C2 |
| | | | |
V | V | V
AES | AES | AES
| | | | | (= C1 XOR A)
V | V | V
|... IV bytes ...|---> XOR +------> XOR +------> XOR
| | |
V V V
|comment1=cooking| | <gibberish> | | T |
So here we now have a chosen ciphertext attack where we can control an entire block of the plaintext without knowing the key. This again highlights the importance of ensuring ciphertext integrity by e.g. computing a MAC over the ciphertext and verifying it before decrypting the ciphertext. Putting it all together we have our solution for the last challenge in set 2.
from os import urandom
from challenge02 import xor
from challenge10 import aes_cbc_decrypt
from challenge11 import aes_cbc_encrypt
from Crypto.Cipher import AES
key = urandom(AES.block_size)
iv = urandom(AES.block_size)
def set_and_encrypt_data(user_data: bytes) -> bytes:
sanitized = user_data.replace(b';', b'%3B').replace(b'=', b'%3D')
comment1 = b'comment1=cooking%20MCs;userdata='
comment2 = b';comment2=%20like%20a%20pound%20of%20bacon'
user = comment1 + sanitized + comment2
return aes_cbc_encrypt(user, key, iv)
def is_admin(encrypted_data: bytes) -> bool:
user = aes_cbc_decrypt(encrypted_data, key, iv)
user_object = {}
for field in user.split(b';'):
field_name, value = field.split(b'=')
user_object[field_name] = value
return user_object.get(b'admin') == b'true'
def replace_ciphertext_block(target: bytes, ctxt: bytes, user_data: bytes) -> bytes:
target_ciphertext_block = ctxt[AES.block_size:2 * AES.block_size]
decrypted_before_xor = xor(target_ciphertext_block, user_data) # AES(C2)
modified_ciphertext_block = xor(target, decrypted_before_xor) # C1'
start = ctxt[:AES.block_size]
end = ctxt[2 * AES.block_size:]
return start + modified_ciphertext_block + end
def challenge16():
user_data = b'A' * AES.block_size
target = b'dataz;admin=true;'
encrypted = set_and_encrypt_data(user_data)
modified = replace_ciphertext_block(target, encrypted, user_data)
assert is_admin(modified)
print("Created object with admin=true")